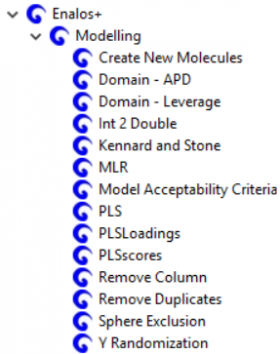
Modelling nodes
Modelling contains 14 nodes specified for data handling, preprocessing, testing modeling robustness and testing the accuracy of the predictions:
- Create New Molecules
Create New Molecules enables the user to create a list of molecules by combining a series of substituents with a core molecule.
- Domain-APD
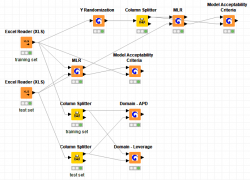
Domain APD enables the user to define the domain of applicability of the model using a method based on the Euclidean distances.
- Domain-Leverage
Domain Leverage enables the user to define the domain of applicability of the model using a method based on the extent of extrapolation
- Int 2 Double
Int 2 Double converts integer values of all columns to doubles.
- Kennard and Stone
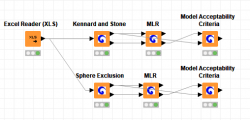
Kennard-Stone node allows the selection of two representative subsets (as training and test sets) with a uniform distribution over an initial dataset.
- MLR
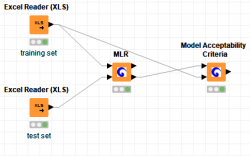
MLR node performs Multiple Linear Regression in order to model the relationships between a scalar dependent variable y and two or more independent variables denoted as X.
- Model Acceptability Criteria
Model Acceptability Criteria gives information about the Quality of Fit and Predictive Ability of a continuous QSAR Model.
- PLS
PLS node, performs Partial Least Squares (PLS) regression analysis by applying the SIMPLS algorithm.
- PLSLoadings
PLSLoadings node, performs the calculation of the loadings on the given data by applying the SIMPLS algorithm.
- PLSscores
PLSScores node, performs the calculation of the scores on the given data by applying the SIMPLS algorithm.
- Remove Column
Remove Column node removes the selected input columns of the table that contain the same values at a percentage equal or higher than a specified cutoff limit.
- Remove Duplicates
Remove Duplicates enables the user to remove the rows of the input table that contain the same values in selected columns. The filtered table contains all rows that are unique and the first one of each repeated row.
- Sphere Exclusion
Sphere Exclusion node allows the selection of two representative subsets (such as training and test sets). This method attempts to specify compounds which most effectively cover the available data space.
- Y-Randomization
Y Randomization (or Y-scrambling) is a technique, applied to ensure a QSAR model’s robustness.
- EnaloskNN
EnaloskNN node employs the k-nearest neighbors method for classification and regression. The prediction for the unknown endpoint of an instance is the value of the weighted average (in regression) or the majority vote (in classification) of the endpoints of the k nearest neighbors in the feature space.